The goal of this part of the assignment is to be able to use SPSS statistical software to run correlations and make correlation matrices, and interpreter the results.
Figure 1 shows a correlation matrix made using SPSS, which shows the correlation between different racial groups, median household income and job sectors.
For context, the data categories were as follows, all from Milwaukee County:
White - White population for the Census Tracts
Black - Black population for the Census Tracts
Hispanic - Hispanic population for the Census Tracts
MedInc - Median Household Income
Manu - Number of Manufacturing Employees
Retail - Number of Retail Employees
Finance - Number of Finance Employees
 |
| Figure 1 - Correlation Matrix made using SPSS, showing correlation between race and job sector in Milwaukee, Wisconsin. |
From the results, we can see that there is a correlation between the number of manufacturing jobs and retail employees, and finance employees. Likewise, there is a correlation between the number of financial employees and retail employees.
In the financial sector, there is a positive correlation between white people and number of finance employees, and a negative correlation between black and hispanic people and finance employees. This could be because of societal prejudice against black and hispanic people in Milwaukee county, and could also be due to the fact that less people from these racial groups have access to the higher education opportunities that would allow them to become employed in the financial sector.
Interestingly, there is a negative correlation between the number of black people in a census tract and the number of white or hispanic people in the census tract. Milwaukee is well known to be the most racially segregated city in the United States, and these statistics seem to hold true to this. This suggests that areas of Milwaukee where the black population live tend to be majority black areas. There is, however, a positive correlation between the number of white people and hispanic people in Milwaukee census tracts, which suggests that the African American population in Milwaukee is more segregated than the White or Hispanic populations.
Part 2
For the second part of assignment 5, we were asked to prepare a report for the Texas Election Commission.
Introduction
The Texas Election Commission (TEC) has tasked us with analyzing election data from the years 1980 and 2016, based on election turn out and percentage democratic vote, in order to establish whether or not patterns exist. Furthermore, they have requested that we look into settlement patterns of Hispanic people from the 2015 census, to see if there is any pattern between this and the voter turnout and percent Democrat vote. This will allow us to see how the distribution of Hispanic populations affects elections in Texas, as well as how voting patterns have changed in the state over the thrity-six year period between 1980 and 2016.
Methods
Results were achieved using data provided by the TEC showing voter turn out and percent Democratic vote and data downloaded from the US census bureau's 2015 concerning the Hispanic population in Texas counties.
SPSS software was used to create a correlation matrix with the data provided by the TEC, to give a preliminary indication of whether or not there has been a change in election patterns between the 1980 election and the 2016 election. SPSS was also used to look for a correlation between the percentage Hispanic population and the 2016 election data they provided.
To give spatial context to these results, GeoDa was used to create Local Indicators of Spatial Autocorrelation maps, otherwise known as LISA maps. These maps are based on the principal of Moran's I, which compares the values of a variable at one location, in this case within a county, to the value of the same variable at another location. When displayed on a LISA map, this can give a clear indication where clustering occurs. The LISA mpas were created using a shapefile for Texas counties downloaded from the US Census Bureau.
Results
Figure 2 shows the correlation matrix for the voter turn outs and percentage Democrat vote from the 1980 and 2016 elections.
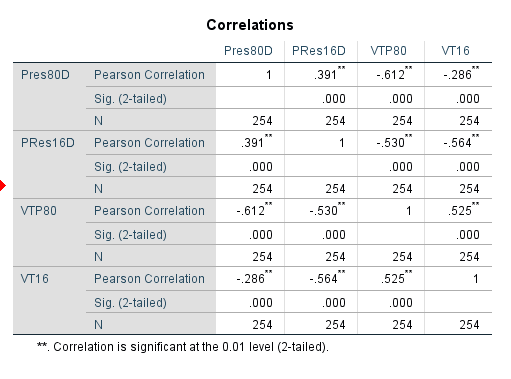 |
| Figure 2 - correlation matrix showing the strength of correlation between the voter tun out and percentage democratic votes from 1980 and 2016. |
There is, however, a negative correlation between voter turn out and percent Democrat vote for both the 1980 and 2016 elections (-.612 and -.564 respectively). This indicates that as voter turnout increases, the percentage of votes won by the Democrats decreases. This suggests that between 1980 and 2016, the voters of Texas have been more likely to vote Republican.
To see how Hispanic voters affected this in the 2016 election, a correlation matrix was created using the 2016 data provided by the TEC and the data taken from the 2015 census to illustrate this (Figure 3).
 |
| Figure 3 - Correlation Matrix for Percent Democrat Vote 2016, Voter Turnout 2016 and Hispanic Population recorded during 2015 census across counties in Texas. |
In order to give spatial context to these results, GeoDa was used to look for clustering.Figure 4 shows the percentage democratic vote in 2016, while figure 5 shows the percentage democratic vote for 1980.
 |
| Figure 4 - LISA Map showing spatial auto-correlation of percentage democratic vote from the 2016 Texas presidential election. |
 |
| Figure 5 - LISA Map showing spatial auto-correlation of percentage democratic vote from the 1980 Texas presidential election. |
In the maps above, blue indicates that these are counties with high democratic votes surrounded by other areas of high democratic votes. The red indicates counties with low democratic votes surrounded by other counties of low democratic votes. The pale blue and red indicate that these counties are not similar to their surrounding counties. The grey counties do not have a significant spatial auto-correlation. This is illustrated in the legend GeoDa produces to go alongside the spatial auto-correlation maps (Figure 6).
 |
| Figure 6 - LISA Map Legend |
Next, the following figures 7 and 8 show the spatial auto-correlations of the voter turnout across Texas for the years 2016 and 1980 respectively.
 |
| Figure 7 - LISA Map showing spatial auto-correlation of voter turn out across Texas counties for the 2016 Presidential election. |
 |
| Figure 8 - LISA Map showing spatial auto-correlation of voter turn out across Texas counties for the 1980 Presidential election. |
From figures 7 and 8, we can see that the south of the state has a consistently high voter turnout, as indicated by the dark blue color of the counties here. This has remained consistent between 1980 and 2016, and is also an area where the percentage Democratic vote has remained consistently low between 1980 and 2016, which suggests that this area of the state is a Republican stronghold.
The rest of the state does not show any areas that indicate a strong pattern between 1980 and 2016, aside from the are north of the aforementioned Republican stronghold, where votes are low and have remained consistently low.
Next, the voter turnout and percentage democratic vote was compared with the Hispanic population of the state (Figure 9).
 |
| Figure 9 - LISA Maps showing, from left to right: Percentage democratic vote, 2016; Voter Turnout, 2016; and Hispanic Population, 2015. |
Conclusion
While spatial patterns are evident between the voter turnout and percentage democrat votes in Texas, as can be see from both the SPSS correlation matrix and the LISA maps, the Hispanic population do not appear to have a significant impact on the result of elections, as shown by the grey colour on the LISA maps that indicate areas of high Hispanic population are not significant in terms of democrat votes. This is despite the fact that the SPSS correlation shows there is a positive correlation between the number of Hispanic people in a county and the percentage Democrat vote. This suggests that despite Hispanic people being more likely to vote Democrat, they do not have much of an influence on the overall outcomes of elections.
Sources
http://www.governing.com/topics/politics/gov-milwaukee-most-segregated-polarized-place.html
US Census Bureau.
Texas Election Commission.
